用 DKnownAI Guard 提供面向 Agent 的对话风控模型;
“融入Agent开源生态+深知对话安全风控模型”——彩智致力于打造Agent专用的AI原生安全机制
时间:2026-6-26
作者:小智
分类:新闻
新一代智能体的安全问题
不能只靠一个模型解决
不能只靠一个模型解决
新一代智能体正在快速进入真实工作流。
从小龙虾、Hermes,到 WorkBuddy 等平台,Agent 已经不再只是“会聊天的模型”。它们开始调用工具、读取文件、访问网页、连接系统流程,也开始通过 Skill、Plugin
等方式,把更多专业能力组织进连续的任务链路中。
这让智能体变得更能干,也让安全问题变得更复杂。
过去我们谈大模型安全,更多关注的是模型回答里有没有违规内容,或者模型会不会拒绝危险请求。但在新一代智能体场景中,真正关键的问题已经变成:
智能体会不会被诱导泄露系统提示词?
会不会被外部网页、文档、邮件里的隐藏指令操控?
会不会在调用工具、读取文件、连接接口之前,缺少一道真正有效的安全判断?
会不会因为缺少框架级机制,让安全模型即使识别出风险,也无法在正确位置拦住风险?
因此,新一代智能体的安全,不是一个单点问题,而是一套系统工程。
新一代智能体安全
需要三个方面
需要三个方面
第一,需要一个真正懂 Agent 风险的安全模型。
智能体安全不能只看关键词,也不能只判断单轮对话是否违规。它需要识别提示词注入、系统提示提取、角色劫持、伪造授权、工具滥用、敏感信息诱导、内容合规等多类风险。
更重要的是,它要理解 Agent 的任务边界。很多请求单独看可能并不明显危险,但放到多轮上下文、工具调用和系统资源访问中,就可能变成一次真实攻击。所以,Agent
安全模型要解决的不是“文本像不像风险”,而是“这条输入会不会让智能体做出不该做的事”。
第二,智能体自身需要 Hook 等安全介入机制。
安全模型再强,也必须能进入智能体执行链路。
如果安全判断只能发生在模型回答之后,或者只能在最外层做简单输入过滤,就很难覆盖 Agent 真正危险的环节。对智能体来说,最关键的位置往往是在模型分发、工具调用、文件读取、外部接口访问之前。
也就是说,智能体框架本身必须提供足够靠前、足够稳定、足够可扩展的安全介入点。没有这样的机制,安全模型只能停留在外部,无法真正守住智能体的行为边界。
第三,需要一个开放的桥梁,把智能体和安全风控模型连接起来。
现实中,不同团队会使用不同智能体框架、不同安全模型、不同部署方式。如果每个团队都重新写一套接入逻辑,开发成本高,维护成本高,也很难形成生态复用。
Agent 安全需要一个开放、可替换、可扩展的桥接层,让安全能力能够以统一方式进入智能体工作流。
换句话说,新一代智能体安全至少要同时具备三件事:
一个懂 Agent 风险的安全模型;
一个能在执行前介入的智能体机制;
一个连接智能体与安全模型的开放桥梁。
一个能在执行前介入的智能体机制;
一个连接智能体与安全模型的开放桥梁。
过去,包括小龙虾等新一代智能体在内,这套能力并不充分。安全判断往往停留在模型外部,或者停留在输入输出层面,缺少真正进入智能体执行链路的机制,也缺少一个稳定、开放、可复用的连接方式。
这正是彩智科技深知团队选择投入的方向。
我们认为,Agent 安全不应该是少数团队闭门实现的一套私有逻辑。它应该充分遵循开源的心态和态度,让安全能力进入框架、进入插件、进入开发者生态,成为新一代智能体基础设施的一部分。
围绕这三个方面,深知团队做了三件事。
01#
DKnownAI Guard
彩智科技深知团队
推出 DKnownAI Guard:
面向新一代智能体的对话风控模型
面向新一代智能体的对话风控模型
针对“需要一个懂 Agent 风险的安全模型”这一问题,深知团队推出了 DKnownAI Guard。
DKnownAI Guard 不是传统意义上的通用内容审核工具,而是面向 Agentic 场景设计的对话风控模型,重点服务于小龙虾、Hermes、WorkBuddy 等智能体和 Skill 化工作流中的安全判断需求。
它关注的不是“文本像不像风险”,而是:
这是不是在操控 Agent?
这是不是在诱导泄露系统信息?
这是不是在推动 Agent 执行高风险操作?
这是不是涉及违法违规、有害内容或欺诈内容?
这是不是一个合法但高影响、需要确认或降权处理的系统请求?
为此,DKnownAI Guard 将智能体场景中的风险划分为更适合开发者使用的类型。
AGENT_HACK
用于识别越狱、提示词注入、系统提示提取、角色劫持、伪造授权、诱导绕过工具规则等操控智能体本身的风险。
SYS_FLAG
用于识别凭证、环境变量、日志、文件、权限、配置、工具调用记录、外部接口等系统层面的高风险请求。
CONTENT_FLAG
用于识别诈骗话术、钓鱼内容、违法活动、危险行为指导、恶意代码等内容合规风险。
SAFE
则表示当前输入没有明显风险,可以正常进入智能体流程。
这种分类让开发者不必只在“放行”和“拒绝”之间做粗糙选择,而是可以根据不同风险类型,采取拦截、确认、降权、脱敏、人工复核或正常放行等不同策略。
这种能力并不是停留在概念层面。
此前,DKnownAI Guard 已经围绕 Agentic 场景发布公开对比测评,并同步公开论文与数据集。这次测评不是简单拿几组测试题做比较,而是直接把问题放到更贴近真实攻击场景的位置,去看各家产品在实战里的表现。
测评从 8 个公开安全数据集中抽样 1,018 条样本,并结合真实部署语境进行了人工复审与重标注,最终形成统一的 BLOCKED / ALLOWED 比较框架。
在与 AWS Bedrock Guardrails、Azure Content Safety、Lakera Guard 的统一评测中,深知安全风控在两个关键指标上同时领先:
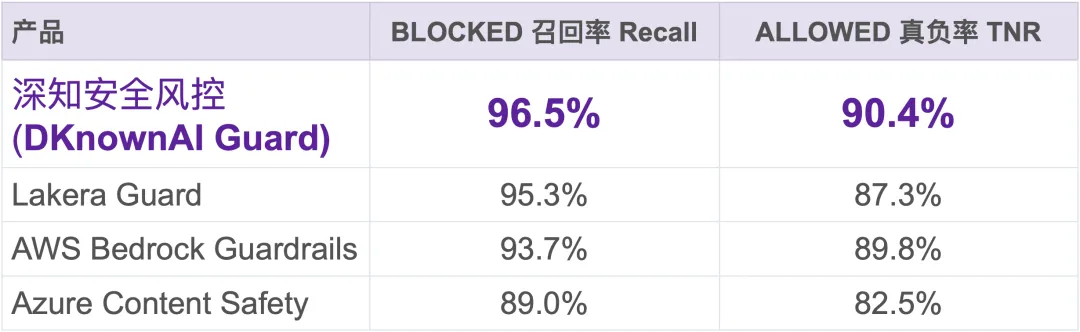
这组结果的意义在于,深知安全风控不仅更能识别真正应该拦截的攻击,也能减少对正常交互的误伤。
对 Agent 来说,这种平衡非常关键。
如果安全模型只追求“拦得多”,会让智能体处处受限,正常任务也被频繁打断;但如果为了体验过度放松,又会留下提示词注入、系统提示泄露、工具滥用等真实攻击面。
真正有价值的 Agent 安全能力,不是简单变得更保守,而是:风险请求坚决阻断,正常任务尽量放行。
02#
DKnownAI Guard
彩智科技深知团队
参与改造 OpenClaw 核心代码:
补上执行前安全介入机制
补上执行前安全介入机制
针对“智能体自身需要 Hook 等安全介入机制”这一问题,深知团队参与了 OpenClaw 核心代码改造。
安全模型要真正发挥作用,必须进入智能体执行链路。尤其是在智能体即将进入模型分发、工具调用、ACP 分发或关键动作执行之前,需要有一个能够介入判断的位置。
此前,深知团队参与提交的 OpenClaw PR #50444 已经合并进入 OpenClaw 主代码。这个 PR 为 OpenClaw 插件系统加入了 before_dispatch hook,让插件可以在路由与策略判断完成之后、模型或 ACP 分发之前介入处理。
这个位置非常关键。
因为它让安全能力不再只是“事后审核”,而可以在智能体行动之前进行判断。
对于提示词注入、系统提示词提取、工具滥用、敏感资源访问等风险来说,执行前判断往往比输出后审核更重要。安全系统如果等到 Agent 已经读取文件、调用接口或完成危险动作之后才发现问题,就已经错过了最关键的位置。
before_dispatch hook 的意义,正是把安全能力放到更靠前的位置,让插件可以在智能体继续执行之前,根据上下文、会话状态、消息内容和策略结果进行判断。
这也是深知团队参与 OpenClaw 核心代码改造的原因:不是站在智能体生态外部做一个旁观式的安全判断器,而是把安全能力真正接入新一代智能体的运行机制中。
03#
DKnownAI Guard
彩智科技深知团队
开源 Guardrail-Bridge:
架起智能体与安全模型之间的开放桥梁
架起智能体与安全模型之间的开放桥梁
针对“需要一个开放桥梁连接智能体与安全模型”这一问题,深知团队推出了独立开源插件 Guardrail-Bridge。
Guardrail-Bridge 的目标,是把安全风控模型接入新一代智能体框架,让 Agent 在真正行动之前,先经过一个可扩展、可替换、可社区共建的安全判断环节。
它要解决的核心问题是:Agent 框架发展很快,但安全模型进入框架的方式还不够统一。
今天,一个团队如果想给智能体接入风控能力,往往需要自己判断在哪个链路拦截、怎么传递上下文、如何处理放行与拦截、不同模型返回结果怎么适配、不同 Agent 框架又如何集成。
Guardrail-Bridge 希望把这件事变得更直接。
它提供的是一个面向 Agent 框架的安全桥接层:DKnownAI Guard 可以通过它接入智能体框架,其他厂商和社区的风控模型也可以基于它接入进来。开发者不需要为每一个模型、每一个框架重新发明一套安全接入逻辑。
这也是 Bridge 这个名字的含义:它连接的是模型与框架,产品与开源,安全能力与智能体生态。
Guardrail-Bridge 不会只被设计成 DKnownAI Guard 的外壳。深知安全风控模型会是其中的重要能力来源,但这个插件的更大价值,是让更多风控模型可以以开放方式进入智能体生态。
不同团队可以选择自己的模型、自己的策略、自己的部署方式,再通过统一插件形态进入 Agent 框架。
这对开发者、模型提供方和框架社区都有意义。开发者可以更低成本地获得 Agent 安全能力;风控模型提供方可以更容易进入正在增长的智能体生态;框架社区则可以把安全能力作为插件生态的一部分持续演进,而不是把所有风险治理都压在单一框架内核里。
我们相信,Agent 安全最终不会只是一家公司的封闭能力,而会成为开源生态中的基础模块。Guardrail-Bridge 正是深知团队面向这个方向迈出的重要一步。
让安全成为智能体
基础设施的一部分
基础设施的一部分
新一代智能体正在从“能不能做出来”,走向“能不能被放心使用”。
当 Agent 获得更大权限,能够调用更多工具、连接更多系统、处理更多真实业务时,安全风控就不再是附加能力,而会成为 Agent 能否进入生产环境的基础设施。
围绕这一问题,深知团队的工作可以概括为三件事:
01
DKnownAI Guard
02
DKnownAI Guard
通过参与 OpenClaw 核心代码改造,补上智能体执行前安全介入机制;
03
DKnownAI Guard
再用 Guardrail-Bridge 架起开放桥梁,让安全模型能够以插件方式进入新一代智能体框架。
这三件事合在一起,才构成了面向 Agent 时代的系统性安全答案。
深知团队将继续围绕 DKnownAI Guard、OpenClaw 生态和 Guardrail-Bridge 开源插件,推动 Agent 安全从概念验证走向真实落地。
我们也希望与更多开发者、框架作者和安全模型提供方一起,让新一代智能体更强,也更值得信任。
彩智科技
公司地址:北京市海淀区中关村东路18号财智国际大厦A座17层
邮编:100081
客服邮箱:sc@czkj1010.com
联系方式:010-62526890
 深知智能公众号
深知智能公众号
 深知智能小程序
深知智能小程序
版权归北京彩智科技有限公司所有
京公网安备11010802046034号
京ICP备16055611号-1